A Partially Observable Markov Decision Process (POMDP) is essentially
a Markov Decision Process without direct access to state [24,18].
Formally, a POMDP is defined as a tuple, ![]() ,
where
,
where ![]() is a finite set of states,
is a finite set of states, ![]() and
and ![]() a set of observations and actions,
a set of observations and actions, ![]() a model of state transition probabilities, and R a function giving
the reward associated with executing a particular action in a particular
state. After executing a particular action
a model of state transition probabilities, and R a function giving
the reward associated with executing a particular action in a particular
state. After executing a particular action ![]() in state
in state ![]() ,
the world transitions to a new state s' with probability Tr(s,a,s'),
and the agent receives a reward R(s,a) and observation
,
the world transitions to a new state s' with probability Tr(s,a,s'),
and the agent receives a reward R(s,a) and observation ![]() with probability Ob(s,a,o). We model state
in the POMDP as the cross-product of world state and and the perceptual
state of the camera,
with probability Ob(s,a,o). We model state
in the POMDP as the cross-product of world state and and the perceptual
state of the camera, ![]() .
In our work we do not assume the system has access to
.
In our work we do not assume the system has access to ![]() ,nor
does it know the transition likelihood between states
,nor
does it know the transition likelihood between states ![]() or the likelihood function mapping states to observations
or the likelihood function mapping states to observations ![]() ;
we leave these unspecified.
;
we leave these unspecified.
We formulate an ``Active Gesture Recognition'' (AGR) task using this
POMDP framework, and have found that instance-based reinforcement learning
is a feasible means for finding good foveation policies. The set of states ![]() describes the various person or object configurations possible in the scene.
Since we have a foveated sensor, we assume that portions of the state of
the world are only revealed via a moving fovea, and that the set of actions
exist to perform that foveation. Some portion of the world state (e.g.,
the low-resolution view) may be fully observable and always present in
the observation. The set
describes the various person or object configurations possible in the scene.
Since we have a foveated sensor, we assume that portions of the state of
the world are only revealed via a moving fovea, and that the set of actions
exist to perform that foveation. Some portion of the world state (e.g.,
the low-resolution view) may be fully observable and always present in
the observation. The set ![]() contains actions for foveation, a special action labeled accept
and a null action. By definition, execution of the accept action
by the AGR system signifies detection of the target pattern in the world.
The goal of the AGR task is therefore to execute the accept action
whenever a target pattern is present, and not to perform that action when
any other pattern (e.g. distractor) is present. A pattern is simply a certain
world state, or more generally a sequence of world states when targets
are dynamic. The AGR system should use the foveation actions to selectively
reveal the hidden state needed to discriminate the target pattern.
contains actions for foveation, a special action labeled accept
and a null action. By definition, execution of the accept action
by the AGR system signifies detection of the target pattern in the world.
The goal of the AGR task is therefore to execute the accept action
whenever a target pattern is present, and not to perform that action when
any other pattern (e.g. distractor) is present. A pattern is simply a certain
world state, or more generally a sequence of world states when targets
are dynamic. The AGR system should use the foveation actions to selectively
reveal the hidden state needed to discriminate the target pattern.
In the AGR task we define the reward function to provide a unit positive
reward whenever the accept action is performed and the target
pattern is present (as defined by an oracle, external to the AGR system),
and a fixed negative reward of magnitude ![]() when accept is performed and a distractor (non-target) pattern
is being presented to the system.
when accept is performed and a distractor (non-target) pattern
is being presented to the system.![[*]](foot_motif.gif) Zero reward is given whenever a foveation action is performed.
Zero reward is given whenever a foveation action is performed.
In reinforcement learning problems we wish to find a policy, a mapping from state (in the case of an MDP) or some function on observations (in the case of a POMDP) to action which maximizes the expected future reward, suitably discounted to bias towards timely performance. An optimal policy maximizes
![\begin{displaymath}Z = \sum_{t=t_0}^{\infty} \gamma^{(t-t_0)} r[t]\end{displaymath}](img14.gif) |
(1) |
| feature | values | observability precondition |
|---|---|---|
| person-present | (true, false) | (always observable) |
| left-arm-extended | (true, false) | (always observable) |
| right-arm-extended | (true, false) | (always observable) |
| face-foveated | (true, false) | (always observable) |
| left-hand-foveated | (true, false) | (always observable) |
| right-hand-foveated | (true, false) | (always observable) |
| face | (neutral, smile, surprise, ...) | face-foveated == true |
| left-hand | (neutral, point, open, ...) | left-hand-foveated == true |
| right-hand | (neutral, point, open, ...) | right-hand-foveated == true |
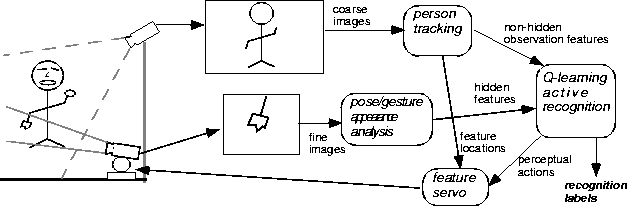
In the interactive interface domain, we have
implemented the AGR task using primitive routines to provide the continuous
valued control and tracking of the different body parts that represent/contain
hidden state. We represent body pose and hand/face state using a simple
feature set, based on the representation produced by a body tracker [28]
and an appearance-based recognition gesture system [9,10].
(See Figure 1(a,b)). We define the world state
(which we also call user state in this domain) to be a configuration of
the user in the scene. ![]() is defined by body pose, facial expression, and hand configurations, expressed
in nine variables (see Table 1). Three of
these are boolean, person-present, left-arm-extended,
and right-arm-extended, and are provided directly by the person
tracker. Three more are provided by the foveated gesture recognition system,
face, left-hand, right-hand, and take on an integer number of
values according to the number of view-based expressions/hand-poses: in
our first experiments face can be one of neutral, smile,
or surprise, and the hands can each be one of neutral,
point, or open. In addition, three boolean features represent
the internal state of the vision system: head-foveated, left-hand-foveated,
right-hand-foveated.
is defined by body pose, facial expression, and hand configurations, expressed
in nine variables (see Table 1). Three of
these are boolean, person-present, left-arm-extended,
and right-arm-extended, and are provided directly by the person
tracker. Three more are provided by the foveated gesture recognition system,
face, left-hand, right-hand, and take on an integer number of
values according to the number of view-based expressions/hand-poses: in
our first experiments face can be one of neutral, smile,
or surprise, and the hands can each be one of neutral,
point, or open. In addition, three boolean features represent
the internal state of the vision system: head-foveated, left-hand-foveated,
right-hand-foveated.
At each time-step, the full state ![]() is defined by these features. An observation,
is defined by these features. An observation, ![]() ,
consists of the same feature variables, except that those provided by the
foveated gesture system (e.g., head and hands) are only observable when
foveated. Thus the face variable is hidden unless the head-foveated
variable is set, the left-hand variable hidden unless the left-hand-foveated
variable set, and similarly with the right hand. Hidden variables are set
to a undefined value. The set of actions,
,
consists of the same feature variables, except that those provided by the
foveated gesture system (e.g., head and hands) are only observable when
foveated. Thus the face variable is hidden unless the head-foveated
variable is set, the left-hand variable hidden unless the left-hand-foveated
variable set, and similarly with the right hand. Hidden variables are set
to a undefined value. The set of actions, ![]() ,
available to the AGR system in this example are 4 foveation commands: look-body,
look-head, look-left-hand, and look-right-hand
plus the special accept action and a null action. Each
foveation command causes the active camera to follow the respective body
part.
,
available to the AGR system in this example are 4 foveation commands: look-body,
look-head, look-left-hand, and look-right-hand
plus the special accept action and a null action. Each
foveation command causes the active camera to follow the respective body
part.
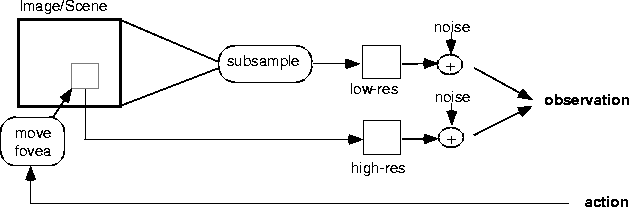
We also have implemented a version of the AGR task with target patterns
which are defined as simple images. In this extended image domain, world
state is simply a single high-resolution image, and the observation consists
of a sub-sampled version of the entire image, plus a full-resolution window
over a foveated region of the image. The fovea is a fixed size rectangle
and can be moved by executing a set of foveation actions. Gaussian noise
with variance ![]() is added to the sub-sampled and windowed images to yield the low and high
resolution observations.
is added to the sub-sampled and windowed images to yield the low and high
resolution observations.
In this domain we use a data-driven process to determine possible actions.
Given a target image and a distribution (or set) of distractors, we sample
distractor images, and compare with the target to determine locations which
can possibly discriminate perceptually aliased pairs. We first normalize
the center of mass of each object image so that actions will be computed
in object-relative coordinates. Each pair of images which is not discriminable
using the low-resolution (fully-observable) portion of the observation
is passed to a high resolution comparison stage. In this stage the images
are compared and all points which differ are marked into a candidate foveation
mask. The marked points in the mask are then clustered, yielding a set
of final foveation targets. These target locations are converted to foveation
actions to fixate at the given coordinate in an image of a new object,
relative to the new object's coordinate frame.
In both domains, when evaluating the performance of an AGR system we present test and training patterns to the learning system interleaved with blank fields. Typically we switched patterns and started a new trial after 10-15 time steps, or after accept was generated.