- ...cost
- Such as the Sony EVI-D30 and the Cannon VCC1.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...system.
- The parameter
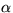 expresses the trade-off between the two types of recognition errors,
false alarms and misses; for the all the results presented in this
paper we have taken a conservative approach and set
expresses the trade-off between the two types of recognition errors,
false alarms and misses; for the all the results presented in this
paper we have taken a conservative approach and set  . This
is somewhat similar to the idea of disproportionately penalizing perceptually
aliased states in Whitehead's Lion algorithm [27].
. This
is somewhat similar to the idea of disproportionately penalizing perceptually
aliased states in Whitehead's Lion algorithm [27].
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...discriminable
- In these examples
observation differences were determined using an ad-hoc
threshold
 (we set
(we set  ) on the variance normalized
average pixel differences between images in the two observations.
) on the variance normalized
average pixel differences between images in the two observations.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...representation.
- Note that
instance-based Q-learning does not assume any knowledge of the set of
states
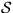 , or the likelihood functions
, or the likelihood functions 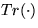 ,
, 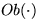 .
..
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...zero.
- Maximum utility can never be
negative, since the null action will always lead to zero or
greater utility (it can be repeated infinitely with zero reward).
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...20.0
- The image range was [0,255].
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...labels.
- Ideally, this would eventually lead to a behavior representation that integrated
discrete and continuous control, such as in [15].
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...selection.
- When merging
two sequences we perform a weighted average of utility, setting the
weight of the merged sequence to be the sum of the individual weights
(which are initialized to 1.) We do modify the Nearest Sequence Match
algorithm such that this weight value is considered when averaging
utility and computing match length histograms.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
- ...level.
- Policies can also be trained simultaneously for
multiple goals, using the approach presented in [11]. For
the purposes of pruning and conversion to representation space,
however, each learned policy is considered separate.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.